Microsoft Azure
A module within Azure Information Protection allows security admins to discover and classify sensitive data stored in the Azure cloud.
Microsoft Azure is a world-leading cloud platform. In 2021, facing competition from Google Cloud and Amazon Web Services, Microsoft Azure urgently needed to offer more advanced features to clients in order to expand its market share. Data compliance is a critical need for modern companies. However, Azure did not have built-in governance tools for sensitive data (such as social security numbers, bank account information, etc.), which led to the loss of clients.
Company:
Microsoft Azure
My Role:
Product Designer
Year:
2020
Service Provided:
PM, VP of Product, Software Engineer
Microsoft Azure is an open, flexible, enterprise-grade cloud computing service. Facing the fierce competition with other cloud services, Azure cloud has a need to improve the user acquisition. The program manager conducted market research and learned that the one of the concerns the enterprise user had is that the Azure function can not support the data compliance feature.
65%
of enterprise users hesitate to adopt Azure due to its incapabilities in data classification for compliance.
By offering scanning services in the
information protection module, Azure
revenues can grow further
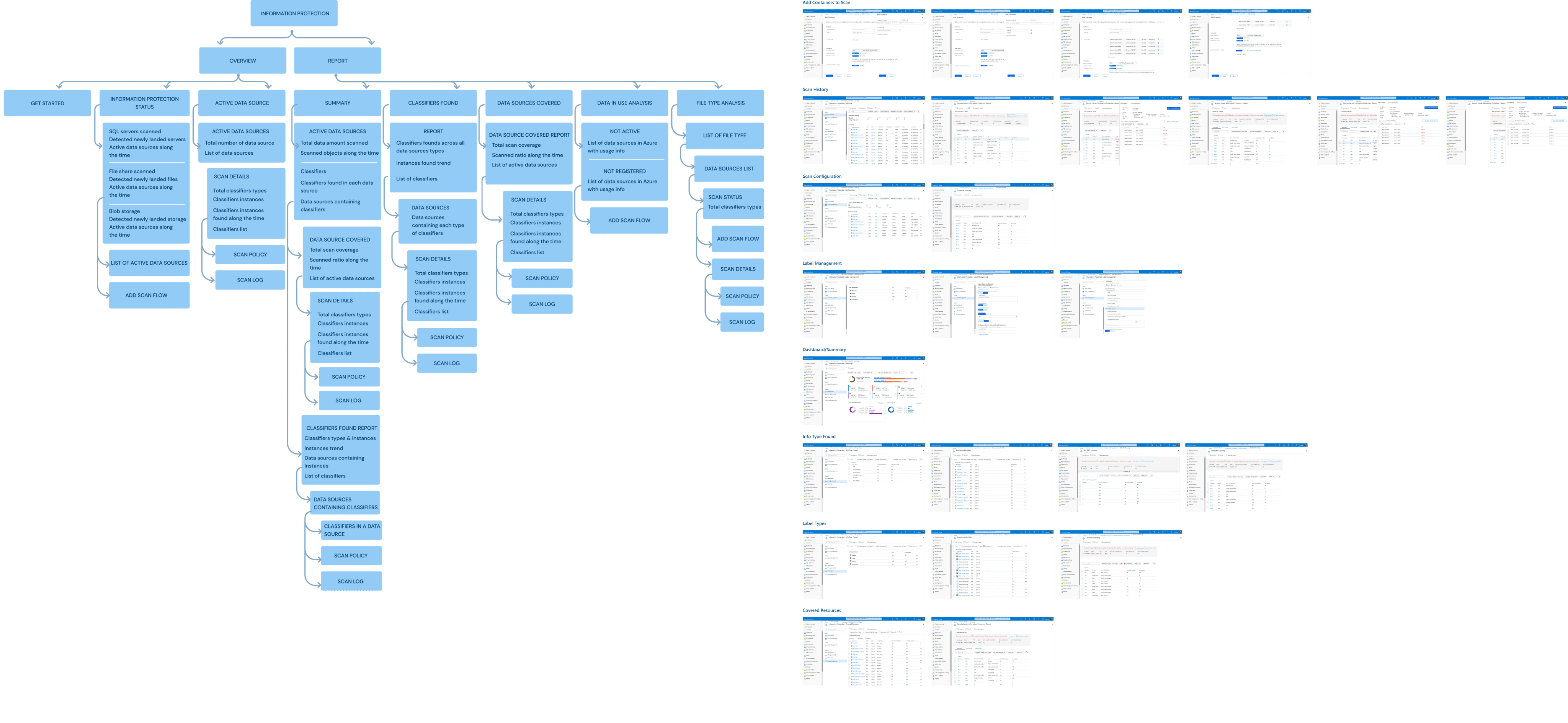
To efficiently deliver the design and communicate the interaction, I created a systematic UI flowchart.

The product users are security admins who are responsible for data loss prevention and make sure the data is compliant. After adopting Azure, they need to make sure the data in cloud is secured and compliant. Their workflow contains 3 major steps. I discovered there were three major pain points. For the first release of this product, the product team decided to focus on the first problem.
Discover
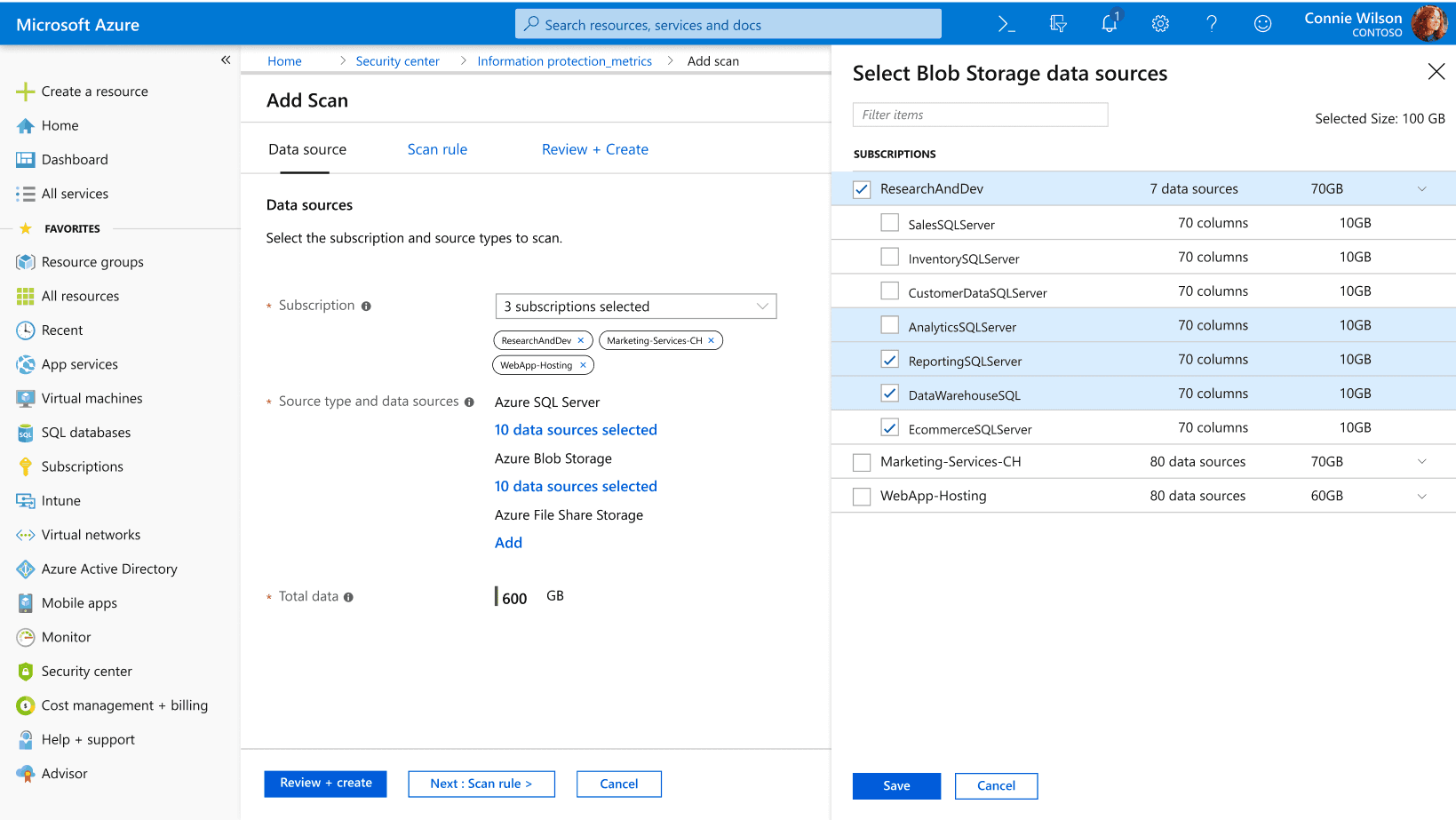
Find out where the sensitive data is located across Azure Blob Storage, Azure storage, and Azure Files
Have limited sight of the confidential data kept in Azure
Classify& Label
Assign predefined labels or tags to data based on its sensitivity and importance. "Confidential," "Internal Use Only," "Public," and "Restricted."
Difficulty in data classification and identification
Protect
Lack access control for
Encryption and data masking
No seamless way to manage the sensitive information stored in Azure for compliance and security purpose
Challenge 1: Product scope is not clear

The information architecture served as a tool to validate my initial assumptions about the user journey and navigation design for the product.
To validate these assumptions and ensure alignment with user needs and expectations, I designed the first version of information architecture to verify my initial assumptions about how would users interact with the product.
I quickly produced mid-fidelity wireframes based on the validated information architecture. These wireframes were crucial in validating the user stories, ensuring they were practical and feasible.
I presented the wireframes to the product management team. It helped them visualize the complexity of the product and they decided to descope the problems solved for users in version 1.
Challenge 2: Lack user research resources at the beginning
I adopted the fast iteration methodology to validate my assumptions along the way. At the later stage of the project, I got usability testing opportunities and tested my assumptions.
Iteration 1 :Navigation Iteration
One specific challenge was designing the navigation panels for the product.
In order to designing an intuitive user journey navigated from the panel, I quickly iterated based on the internal experts’ feedback.
At the later stage, i conducted the usability testings to further validate assumptions.
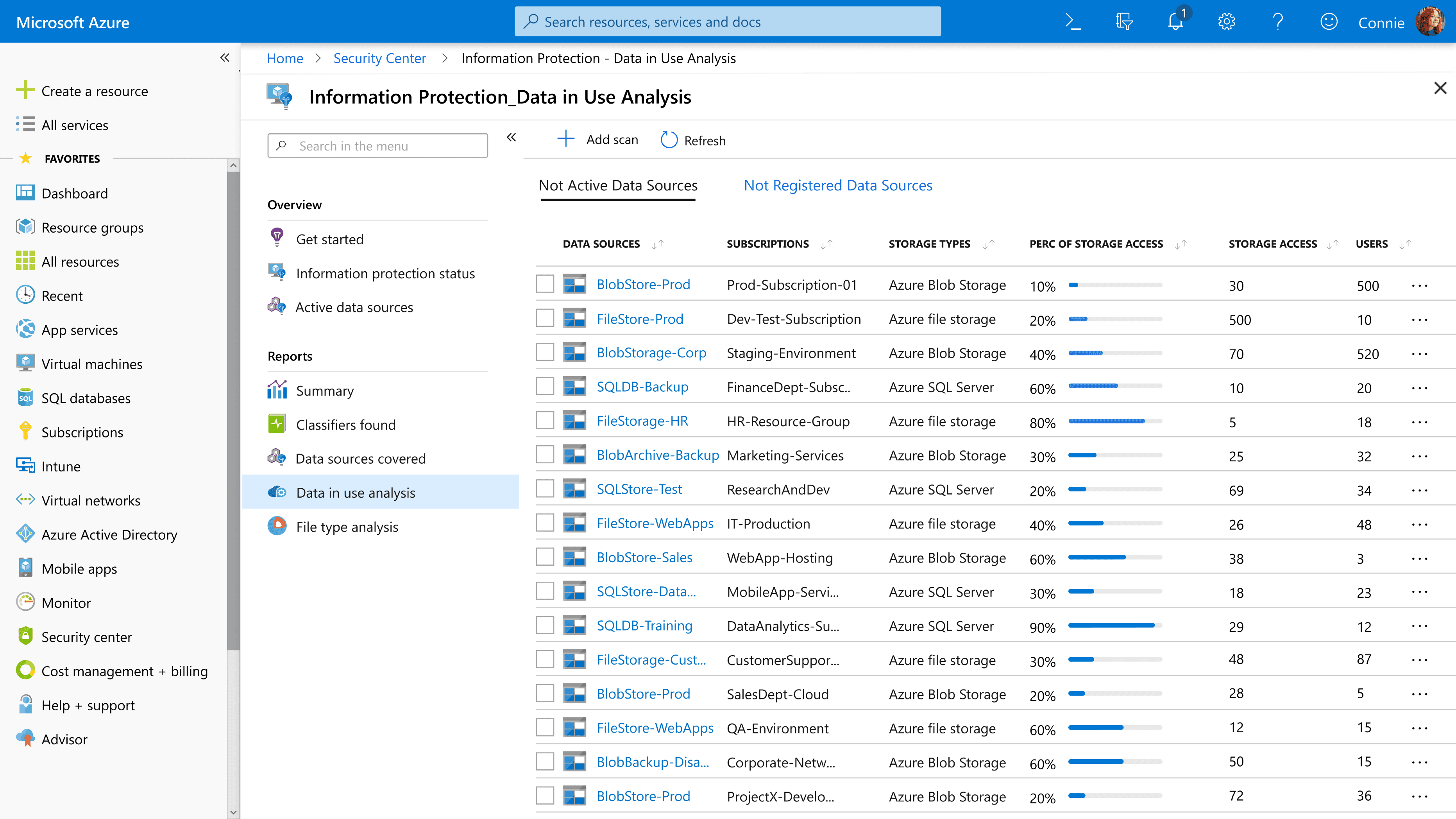
The final design prioritized the frequent action, formed an intuitive user journey.
Search in the menu
Scan
Scannings

Scan configuration
Labels
Label management
Protection
Protection management
Reports
Dashboards
Info types found
Covered resources
Label types
Search in the menu
Overview
Get started
Dashboard
Reports
Classifiers found
Data sources covered
Settings

Scan configuration

Iteration 2: Summary Page Iteration
Another challenge was designing an intuitive and information-rich summary page. Facing ambiguity and uncertainty in understanding users from the start, I ideated features for the first version based on assumptions. During the iteration process, I always kept the following questions in mind:
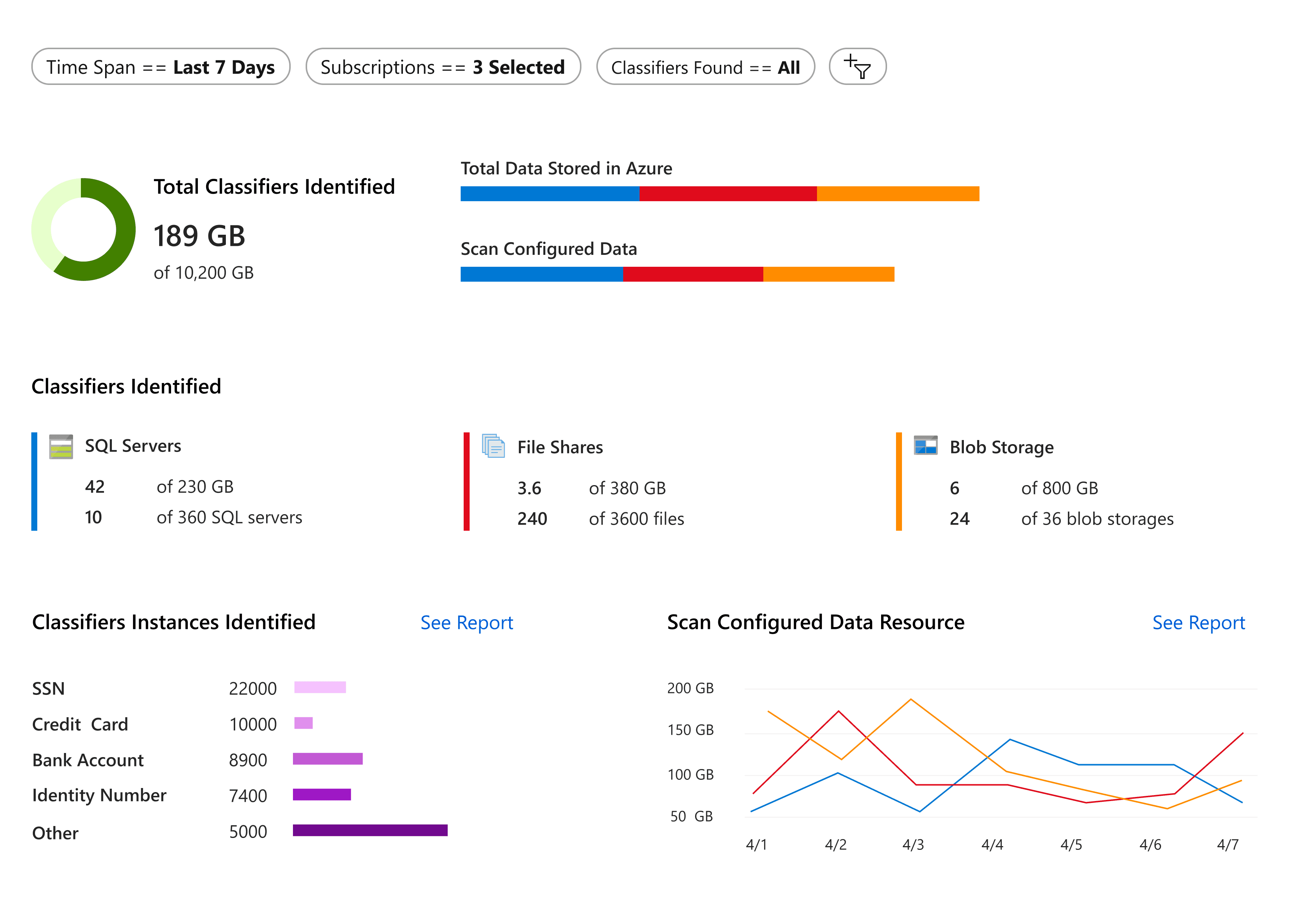
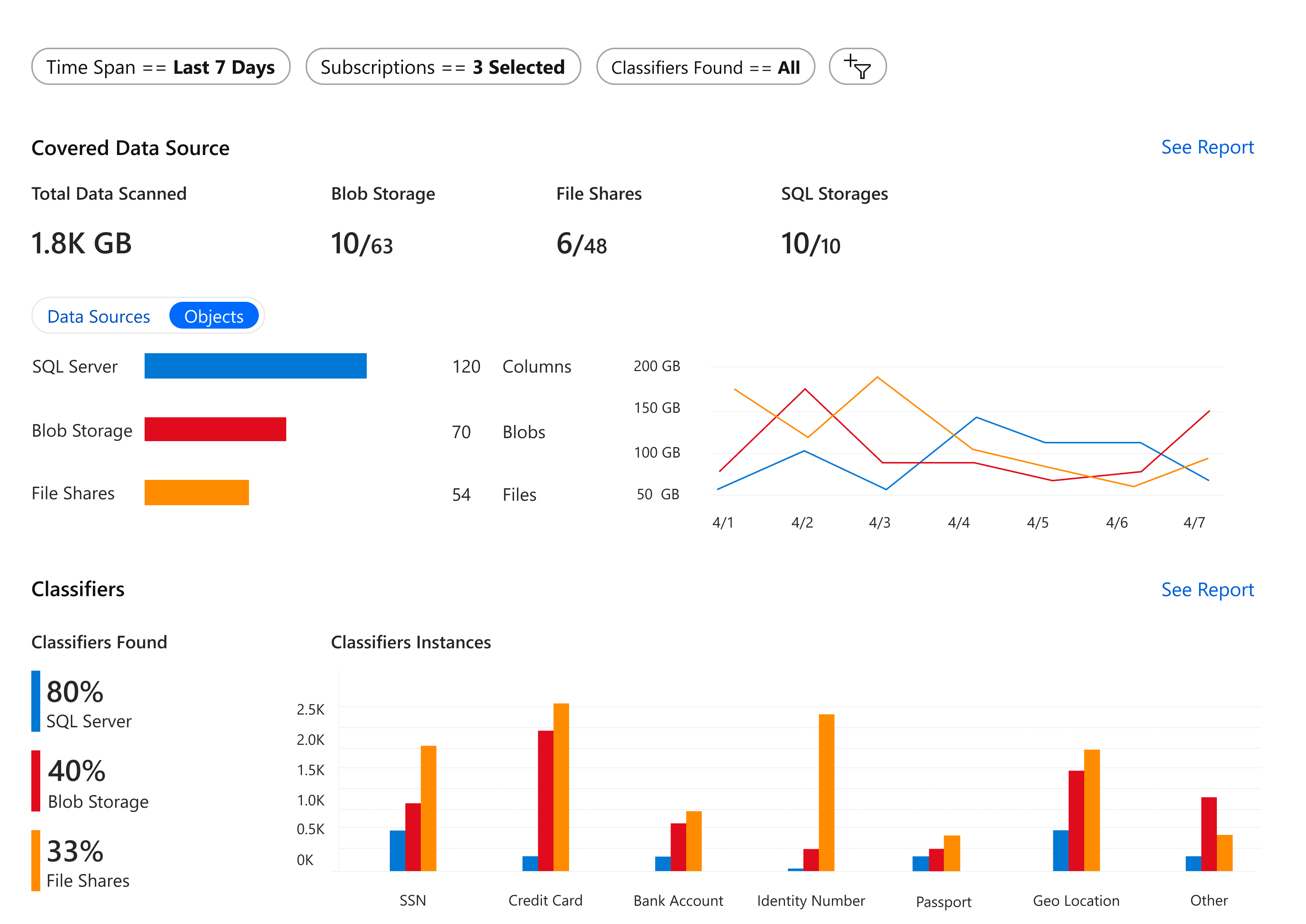
What is the user journey like when reading the summary page?
What data visualization format suits the users' purpose best?
What information is most important for users, and what information would users like to dive into more?
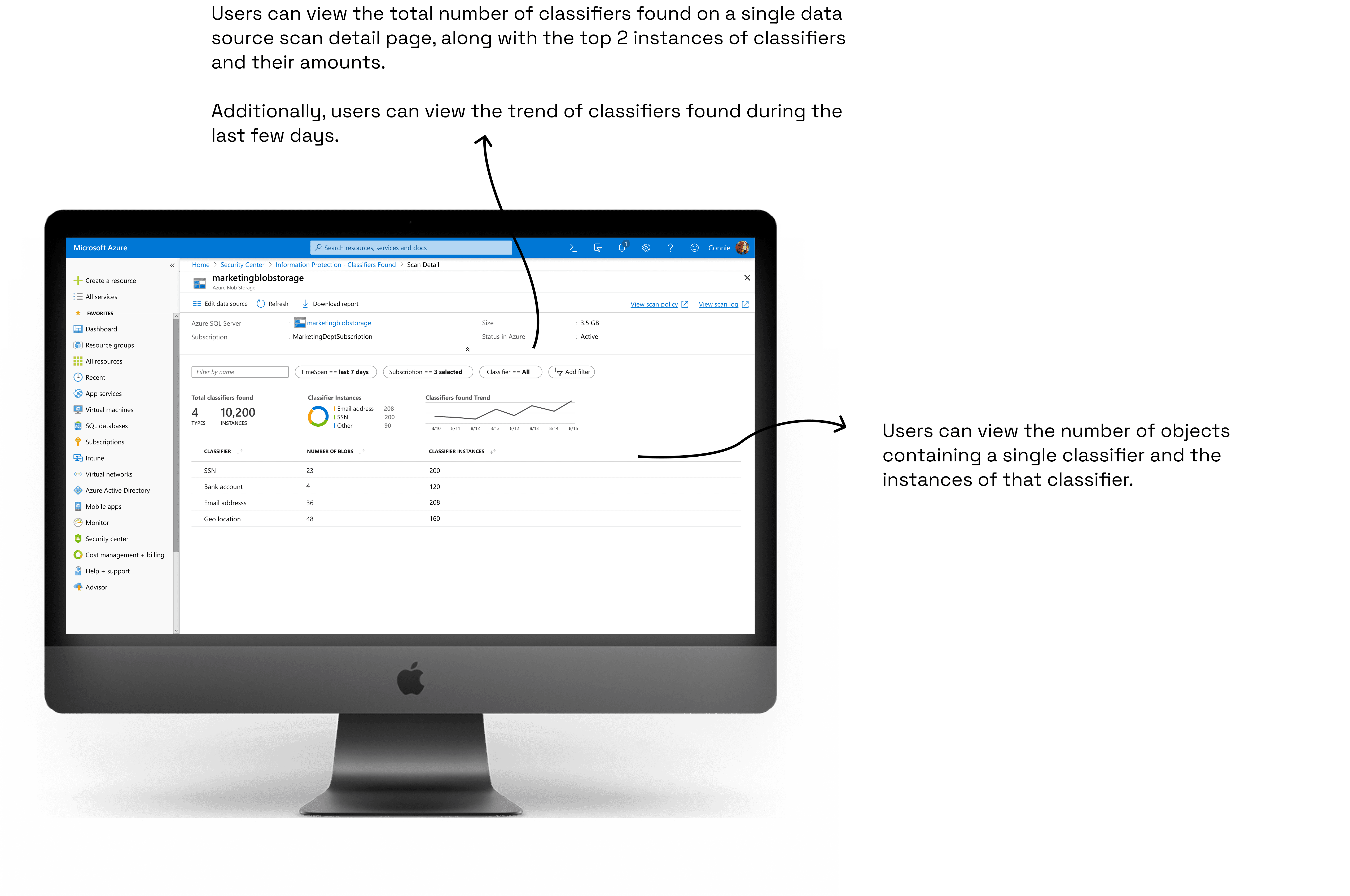
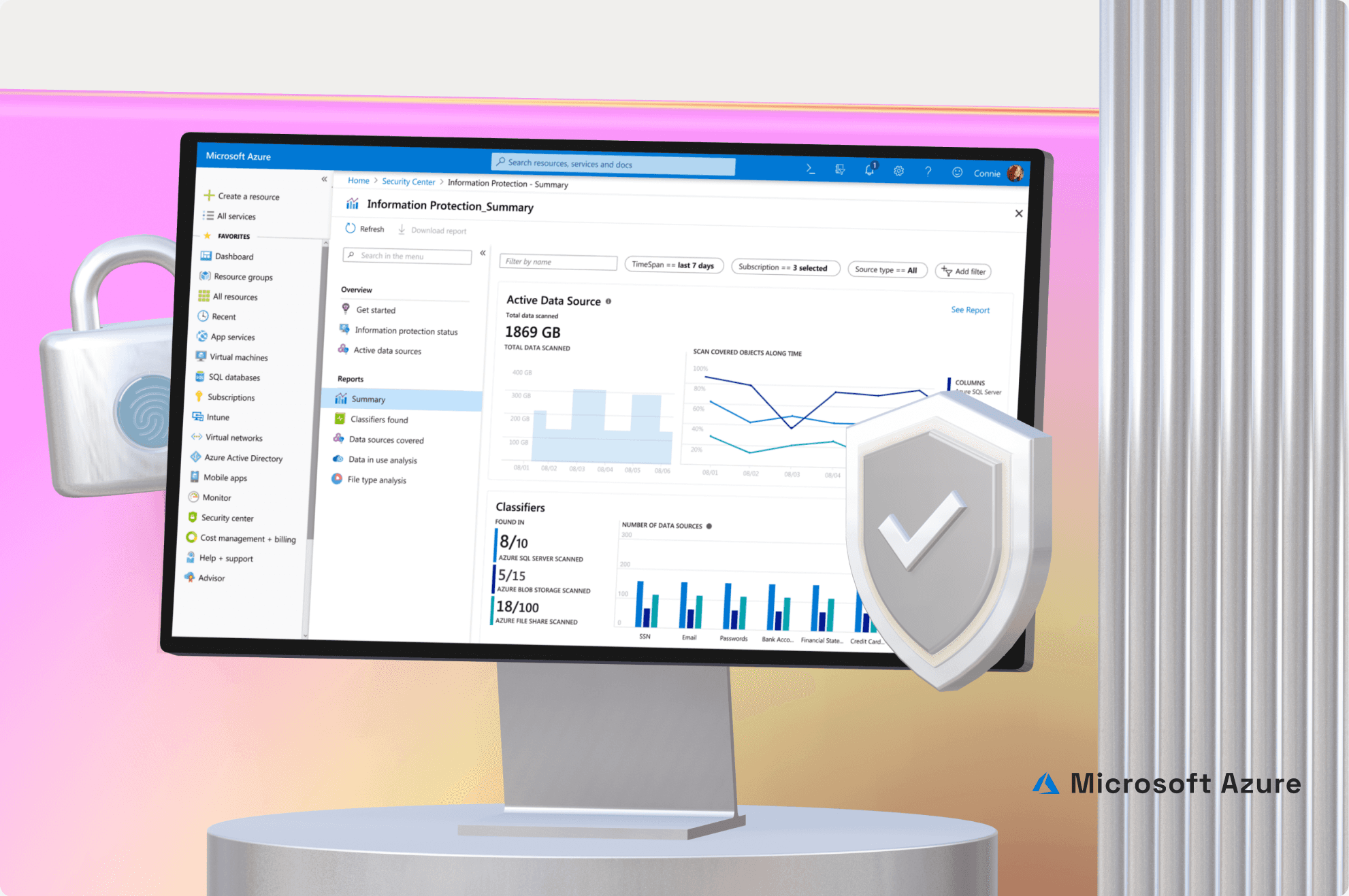
The final summary page design is simple and information-rich. It offers an overview for important information. Users can dive in more detailed information easily from this page.